Remove consumer bias & allow queues under max load to drain quickly #1378
Conversation
|
After about 30-40 runs, I am yet to see one that did not drain within the hour. Typically, the queue gets drained within 10' - 30' Before this changeNotice that the queue is still being drained after 20 hours
After this changeThe queue is drained in 28 minutes:
|

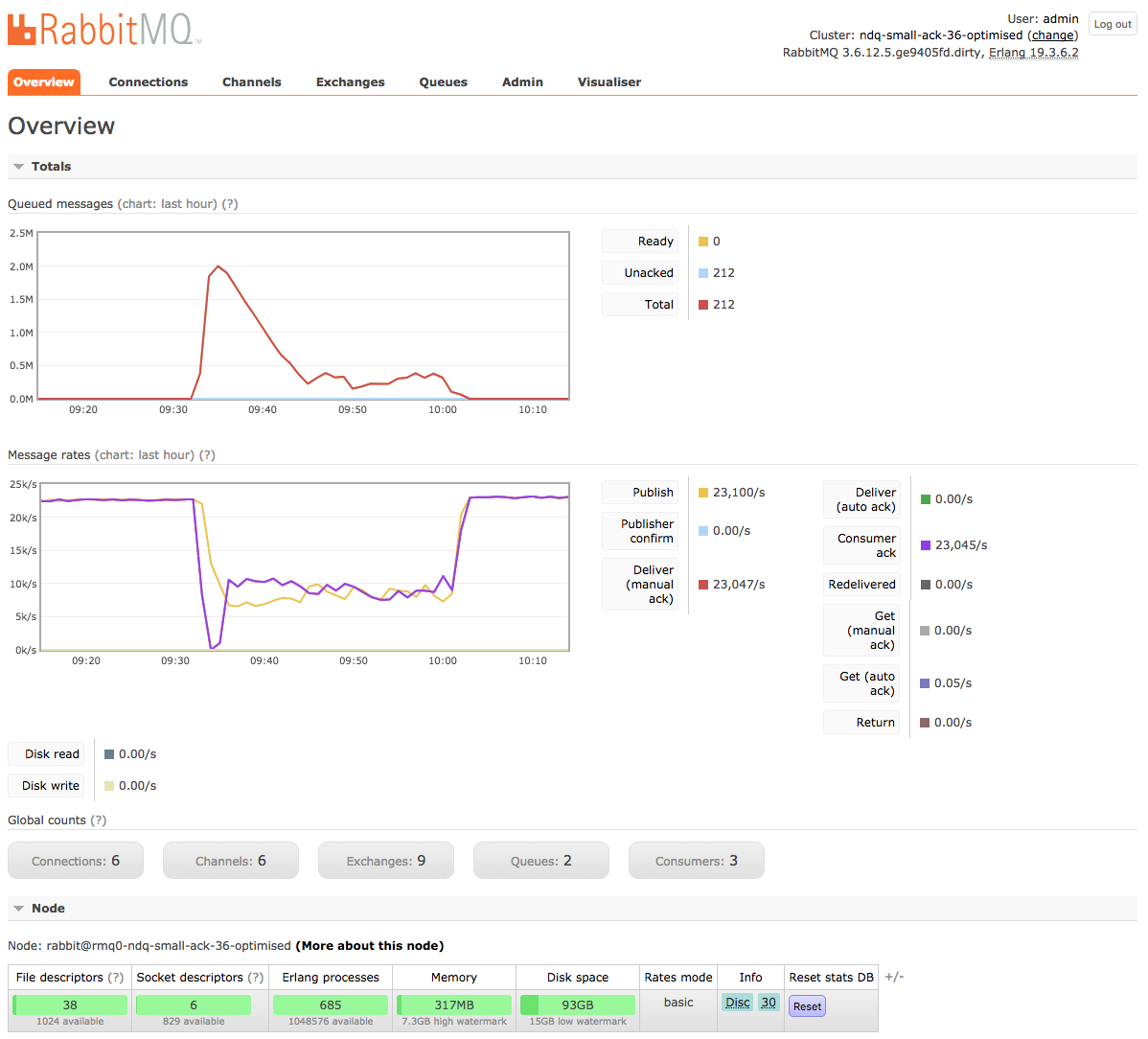


Given a queue process under max load, with both publishers & consumers,
if consumers are not **always** prioritised over publishers, a queue
can take 1 day (or more) to fully drain.
Even without consumer bias, queues can drain fast (i.e. 10
minutes in our case), or slow (i.e. 1 hour or more). To put it
differently, this is what a slow drain looks like:
```
___ <- 2,000,000 messages
/ \__
/ \___ _ _
/ \___/ \_____/ \___
/ \
|-------------- 1h --------------|
```
And this is what a fast drain looks like:
```
_ <- 1,500,000 messages
/ \_
/ \___
/ \
|- 10 min -|
```
We are still trying to understand the reason behind different drain
rates, but without removing consumer bias, this would **always** happen:
```
______________ <- 2,000,000 messages
/ \_______________
/ \______________ ________
/ \__/ \______
/ \
|----------------------------- 1 day ---------------------------------|
```
Other observations worth capturing:
```
| PUBLISHERS | CONSUMERS | READY MESSAGES | PUBLISH MSG/S | CONSUME ACK MSG/S |
| ---------- | --------- | -------------- | --------------- | ----------------- |
| 3 | 3 | 0 | 22,000 - 23,000 | 22,000 - 23,000 |
| 3 | 3 | 1 - 2,000,000 | 5,000 - 8,000 | 7,000 - 11,000 |
| 3 | 0 | 1 - 2,000,000 | 21,000 - 25,000 | 0 |
| 3 | 0 | 2,000,000 | 5,000 - 15,000 | 0 |
```
* Empty queues are the fastest since messages are delivered straight to
consuming channels
* With 3 publishing channels, a single queue process gets saturated at
22,000 msg/s. The client that we used for this benchmark would max at
10,000 msg/s, meaning that we needed 3 clients, each with 1 connection
& 1 channel to max the queue process. It is possible that a single
fast client using 1 connection & 1 channel would achieve a slightly
higher throughput, but we didn't measure on this occasion. It's
highly unrealistic for a production, high-throughput RabbitMQ
deployment to use 1 publishers running 1 connection & 1 channel. If
anything, there would be many more publishers with many connections &
channels.
* When a queue process gets saturated, publishing channels & their
connections will enter flow state, meaning that the publishing rates
will be throttled. This allows the consuming channels to keep up with
the publishing ones. This is a good thing! A message backlog slows
both publishers & consumers, as the above table captures.
* Adding more publishers or consumers slow down publishinig & consuming.
The queue process, and ultimately the Erlang VMs (typically 1 per
CPU), have more work to do, so it's expected for message throughput to
decrease.
Most relevant properties that we used for this benchmark:
```
| ERLANG | 19.3.6.2 |
| RABBITMQ | 3.6.12 |
| GCP INSTANCE TYPE | n1-standard-4 |
| -------------------- | ------------ |
| QUEUE | non-durable |
| MAX-LENGTH | 2,000,000 |
| -------------------- | ------------ |
| PUBLISHERS | 3 |
| PUBLISHER RATE MSG/S | 10,000 |
| MSG SIZE | 1KB |
| -------------------- | ------------ |
| CONSUMERS | 3 |
| PREFETCH | 100 |
| MULTI-ACK | every 10 msg |
```
Worth mentioning, `vm_memory_high_watermark_paging_ratio` was set to a
really high value so that messages would not be paged to disc. When
messages are paged out, all other queue operations are blocked,
including all publishes and consumes.
Artefacts attached to #1378 :
- [ ] RabbitMQ management screenshots
- [ ] Observer Load Chars
- [ ] OS metrics
- [ ] RabbitMQ definitions
- [ ] BOSH manifest with all RabbitMQ deployment properties
- [ ] benchmark app CloudFoundry manifests.yml
[#151499632]
d721d33 to
155eb6b
Compare
Other runs after this change
|




Other runs with
|




Artefacts |
|
Apparently, the number of CPUs (number of Erlang schedulers) is a decisive factor in whether a queue can be drained or not:
I am running exactly the same bechmark on n1-highcpu-16 (was using n1-highcpu-4 before) and the queue is not draining... Not done after all. |

|
The queue drained after about 6 hours...
Investigating further... |

|
@gerhard this is with the default scheduler bind and |
|
This is with the current erl flags, no changes in that respect. In our deployments, since hosts are dedicated to RabbitMQ, we are able to achieve maximum efficiency if we only run publishing channels, meaning no queues, just exchanges (see attached screenshot). I'm profiling
|

|
@michaelklishin would it be worth writing a blog post about this? After all: https://www.rabbitmq.com/blog/2014/04/10/consumer-bias-in-rabbitmq-3-3/ |
|
@gerhard we can update the post we have. There isn't much to say other than "according to whole bunch of experiments and metrics, this change does not work as well as it was supposed to". |
|
@gerhard 👍 |
Given a queue process under max load, with both publishers & consumers,
if consumers are not always prioritised over publishers, a queue
can take 1 day (or more) to fully drain.
Even without consumer bias, queues can drain fast (i.e. 10
minutes in our case), or slow (i.e. 1 hour or more). To put it
differently, this is what a slow drain looks like:
And this is what a fast drain looks like:
We are still trying to understand the reason behind different drain
rates, but without removing consumer bias, this would always happen:
Other observations worth capturing:
Empty queues are the fastest since messages are delivered straight to
consuming channels
With 3 publishing channels, a single queue process starts getting saturated at
22,000 msg/s. The client that we used for this benchmark would max at
10,000 msg/s, meaning that we needed 3 clients, each with 1 connection
& 1 channel to max the queue process. It is possible that a single
fast client using 1 connection & 1 channel would achieve a slightly
higher throughput, but we didn't measure on this occasion. It's
highly unrealistic for a production, high-throughput RabbitMQ
deployment to use 1 publishers running 1 connection & 1 channel. If
anything, there would be many more publishers with many connections &
channels.
When a queue process gets saturated, publishing channels & their
connections will enter flow state, meaning that the publishing rates
will be throttled. This allows the consuming channels to keep up with
the publishing ones. This is a good thing! A message backlog slows
both publishers & consumers, as the above table captures.
Adding more publishers or consumers slow down publishinig & consuming.
The queue process, and ultimately the Erlang VMs (typically 1 per
CPU), have more work to do, so it's expected for message throughput to
decrease.
Most relevant properties that we used for this benchmark:
Worth mentioning,
vm_memory_high_watermark_paging_ratiowas set to areally high value so that messages would not be paged to disc. When
messages are paged out, all other queue operations are blocked,
including all publishes and consumes.
Artefacts attached to #1378 :
[#151499632]